
مواجهه با underfit در شبکههای عصبی
یک شبکه عصبی underfit است وقتی که هنوز نتوانسته به خوبی دادهها را یاد بگیرید. این پدیده به چند علت ممکن است رخ داده باشد. در این مقاله به این علتها و نحوه مواجهه به آنها میپردازیم.
1. underfit چیست
در آموزش شبکههای عصبی ما به دنبال دو چیز هستیم: ۱) بهینهسازی و ۲) عمومیت. منظور از بهینهسازی این است که شبکه عصبی باید بتواند داده های train را به خوبی یاد بگیرد و پارامترهای مورد نیاز خودش را از آنها استخراج کند. با کمک معیارهای ارزیابی (مانند loss، accuracy و fscore) ما میتوانیم ببینیم که آیا شبکه عصبی توانسته دادههای یادگیری را یاد بگیرد یا خیر. نکته دیگر، عمومیت است. در عمومیت ما به دنبال این هستیم که شبکه عصبی بتواند نتایج خوبی بر روی دادههایی داشته باشد که تا به حال ندیده است (دادههای آزمون).
ممکن است که شبکه عصبی نتواند یادگیری خوبی داشته باشد. یعنی نتایج ارزیابی بر روی دادههای یادگیری (train) پایین باشد. در این حالت، نتایج بر روی داده های آزمون هم پایین است. به این حالت underfit شدن میگوییم.
از طرف دیگر، ممکن است که شبکه یادگیری خوبی بر روی داده های یادگیری داشته باشد، اما عمومیت نداشته باشد. به این معنا که نتایج ارزیابی بر روی دادههای یادگیری خیلی خوب است اما همین نتایج بر روی دادههای آزمون خوب نیست. در این میگوییم شبکه overfit شده است.
2. راه تشخیص underfit
برای تشخیص underfit، کافی است که نمودار loss یادگیری (train loss) و loss ارزیابی (validation loss) را بر اساس epoch رسم کنیم. به طور کلی انتظار داریم که نمودار loss یادگیری، نزولی باشد. اگر نمودار loss ارزیابی هم نزولی باشد، یعنی underfit رخ داده است. نمونه نموداری که در آن underfit رخ داده است در شکل زیر نشان داده شده است. همانطور که میبینیم، هر دو نمودار loss، نزولی هستند.
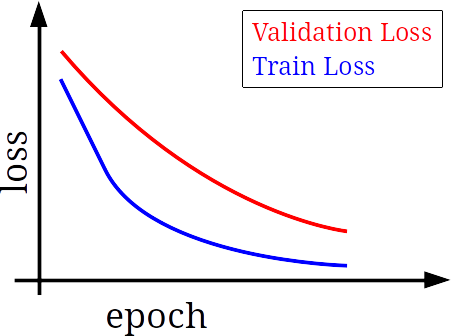
نمودار train loss نشان دهنده بهینهسازی (optimization) و نمودار validation loss نشان دهنده خطای عمومیت (generalixation error) است. هرچه validation loss کمتر باشد، خطای عمومیت کمتر است و به عبارت دیگر، میزان عمومیت بیشتر است.
3. برطرف کردن underfit بودن شبکه
به طور کلی underfit بودن، به سه علت رخ میدهد: ۱) کم بودن تعداد ویژگی دادهها، ۲) یادگیری با تعداد epoch کم و ۳) کوچک بودن مدل. با توجه به این سه علت، برای برطرف کردن underfit باید این سه علت را برطرف کنیم.
3.1. برطرف کردن کم بودن تعداد ویژگیها
برای برطرف کردن کم بودن ویژگی دادهها، باید ویژگی داده ها را افزایش بدهیم. در اکثر موارد این کار امکان پذیر نیست. اما در برخی موارد، امکان ساخت ویژگی جدید بر اساس دادههای موجود وجود دارد. مثلا یکی از راههای ساخت ویژگی جدید، تقسیم دو ویژگی بر روی هم است. مثلا اگر یکی ویژگیهای شما تعداد متغیرها و ویژگی دیگر شما تعداد خط است، با تقسیم تعداد متغیرها بر تعداد خط، ویژگی جدیدی ایجاد میشود که معنا دار هم هست. به طور کلی، این روش ها در موضوعی با نام Feature Engineering مطرح میشود.
3.2. برطرف کردن تعداد epoch کم
برای برطرف کردن یادگیری با epoch کم، کافی است که تعداد epoch ها را افزایش بدهیم. اینکار را تا زمانی ادامه میدهیم که نمودار loss ارزیابی، نزولی باشد.
3.3. برطرف کردن کوچک بودن مدل
کوچک بودن مدل به معنای کم بودن پارامترهای یادگیری است. برای اینکار شما باید پارامترهای یادگیری شبکه را افزایش بدهید. پارامترهای یادگیری در شبکههای عصبی، تعداد و نوع لایهها و تعداد نرون در هر لایه است. بنابراین، کافی است که شما لایههای جدید به شبکه اضافه کنید و یا اینکه تعداد نرونهای لایههای موجود را افزایش بدهید.
4. جمعبندی
وجود underfit اولین مشکلی است که ممکن است شما با آن برخورد کنید. هر چند برطرف کردن underfit نسبتا راحت است، اما دانستن علت آن، به درک بهتر شبکه عصبی کمک میکند. در این مقاله، به علت وجود این پدیدیه و نحوه مواجهه با آن پرداختیم. در مقاله بعد انشالله به نحوه مواجهه با overfit در شبکههای عصبی میپردازیم.